Запросите и получите доступ к демо-системе Memoza.Online, следуя инструкциям ниже:
👉 Перейдите на страницу https://search-centric.com/monline
Обратите внимание, что необходимо вводить рабочий адрес электронной почты для получения доступа.

Ознакомьтесь с общими принципами работы системы Memoza.Online:
📚 Прочитайте онлайн руководство: https://search-centric.com/instruction-01
Поэкспериментируйте с основными функциями, чтобы лучше понять работу системы:
- Поиск по различным критериям
- Сортировка результатов
- Работа с картографическим интерфейсом
• Используйте панель слева для переключения между разделами
• Кнопки фильтрации находятся в верхней части основного окна
• Для просмотра дополнительных опций используйте контекстное меню (правая кнопка мыши)
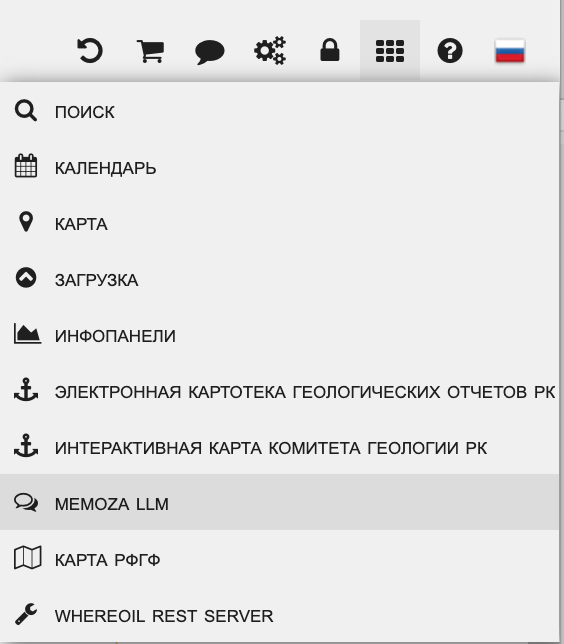
Доступ к интерфейсу Memoza LLM осуществляется через меню «Приложений» (см. изображение).
Для более интересной работы рекомендуется загрузить собственные данные, чтобы опробовать на них LLM, а также инструменты индексации содержимого и OCR Memoza:
Алгоритм работы: загрузить данные → дождаться индексации содержимого → открыть приложение Memoza LLM и начать работу.
Загрузите 3-5 файлов на геологическую тематику. Это могут быть отчеты из открытых данных ЕФГИ, например. (О том, как получить к ним доступ, можно посмотреть здесь).
Рекомендуется начать с небольшого количества файлов (3-5) и небольшого объема (до 100 МБ), чтобы ускорить процесс индексации.
Убедитесь, что файлы поддерживаются системой (описания поддерживаемых форматов в разделе «Memoza Content Service»).
Обязательно загрузите также графические файлы с текстом (PDF, TIFF, JPG), чтобы опробовать работу OCR.
Как загрузить файлы:
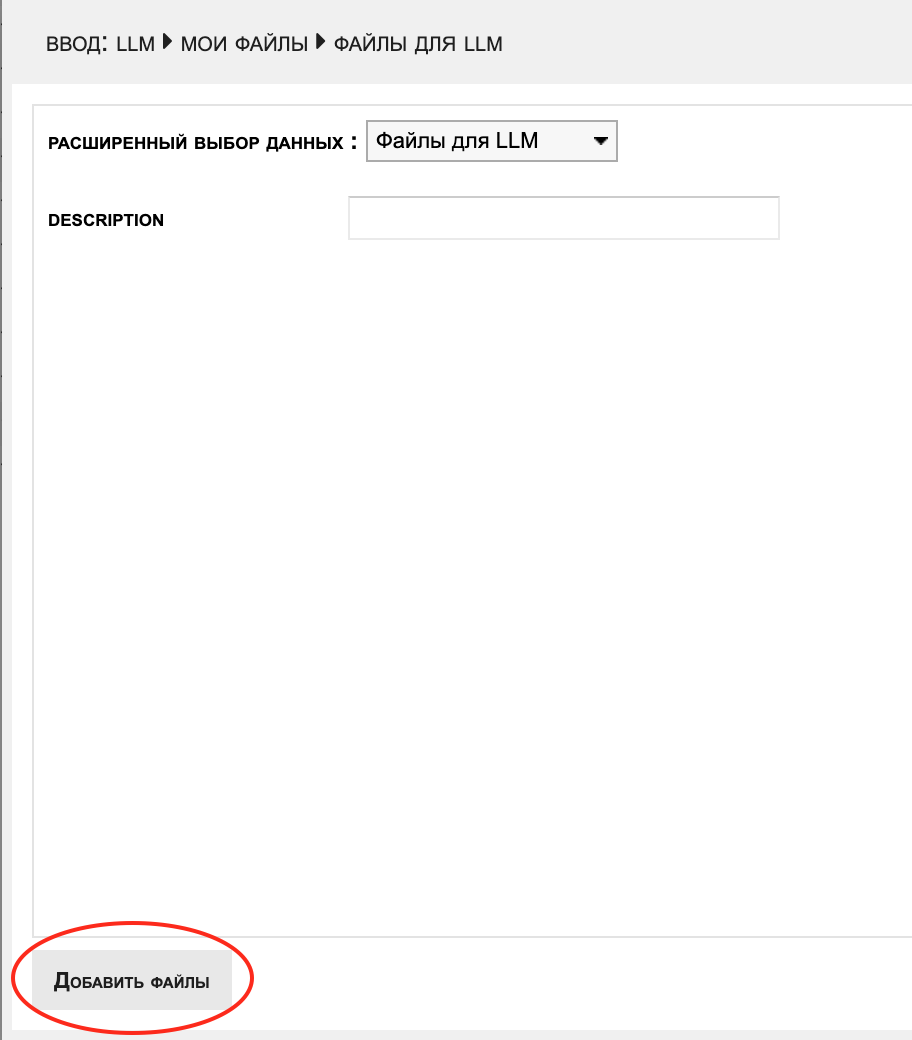
- Нажмите на иконку "фотоаппаратик" на вертикальной панели слева
- Выберите Мои Файлы → Файлы для LLM
- Нажмите кнопку Добавить файлы в нижнем левом углу
- Выберите один или несколько файлов и нажмите Сохранить
- Дождитесь, когда сообщение в правом верхнем углу «Процесс» сменится на «Файлы успешно загружены»
- Повторите, чтобы загрузить больше файлов


Дождитесь завершения контентного и векторного индексирования.
На этом этапе ничего делать не нужно - только ждать.
Индексирование происходит каждый целый час. Время индексирования зависит от размера и количества загруженных файлов (как правило, это несколько минут).
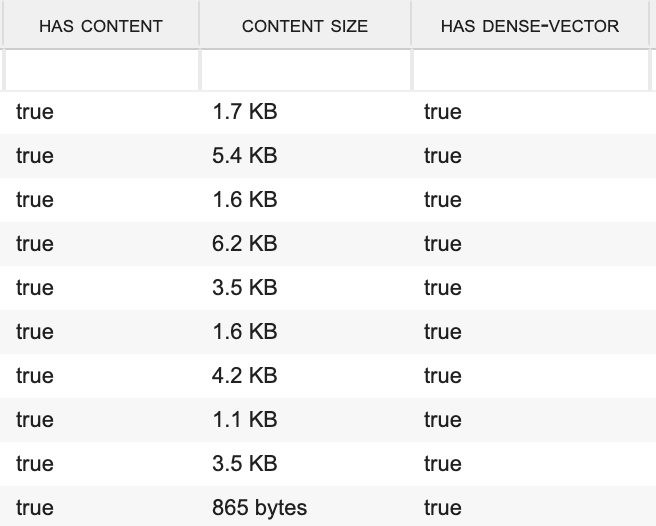
Как убедиться, что файлы проиндексированы?
В колонках "HAS CONTENT" и "HAS DENSE-VECTOR" должно стоять «true», а размер содержимого должен быть отличен от нуля.
Теперь можно воспользоваться поиском, чтобы найти ваши файлы по ключевым словам из их содержимого (функция, которую вы уже изучили в Шаге 1).
Пообщайтесь с конкретным документом через интерфейс Memoza LLM:
- В приложении Memoza LLM (доступ через меню «Приложений») в нижнем левом углу выберите опцию «Документ»
- Убедитесь, что в средней графе указано «Мои файлы / Файлы для LLM»
- В правом нижнем углу введите путь к одному из документов, которые вы загрузили
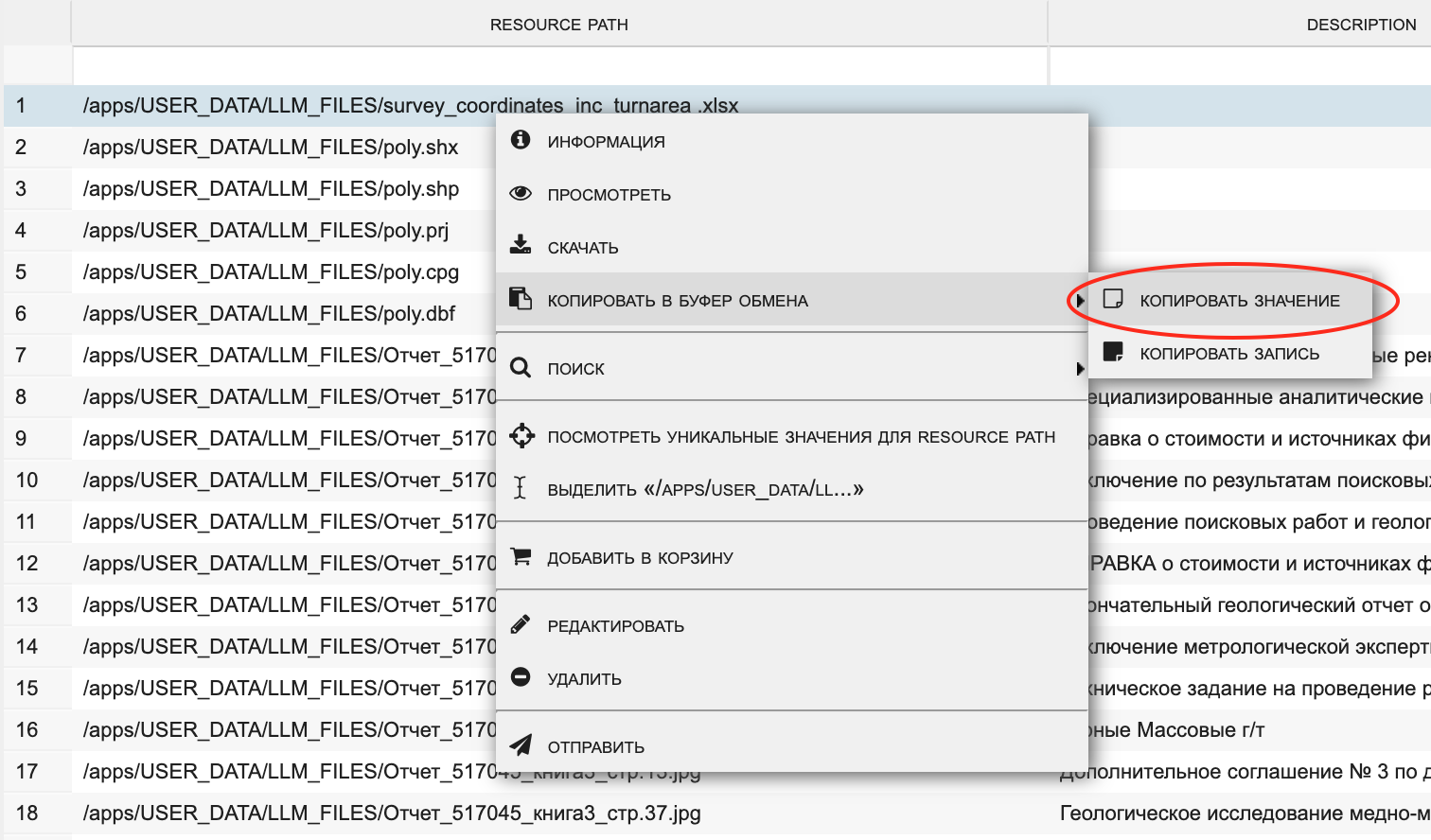
Где взять путь к документу?
- В левой панели откройте схему «Мои файлы», нажав на плюсик
- Выберите класс «Файлы для LLM»
- В основном окне наведите мышку на интересующий файл в колонке «RESOURCE PATH»
- Клик правой кнопкой мыши: Копировать в буфер обмена - Копировать значение
- Вставьте скопированное в буфер в поле «введите путь к документу» интерфейса Memoza LLM
Если своих вопросов не рождается, нажмите на кнопку в правом углу строки ввода и выберите из готовых промптов.
Например:
- «ДЕМО. Лицензионные обязательства» - для договоров на недропользование
- «ДЕМО. Работы по изученности» - для геологических отчетов
Или просто спросите, кто главный герой произведения и чем он интересен, если загрузили научно-фантастический рассказ.
История диалога с LLM влияет на ее последующие ответы. Если вы не хотите учитывать историю диалога - нажмите кнопку «Новый чат» в правом верхнем углу, чтобы начать новый диалог.


В этом режиме вы задаете вопрос LLM, не указывая на конкретный документ, в котором она должна найти ответ. Memoza сначала находит подходящие документы и фрагменты с помощью векторного поиска и поиска по ключевым словам, а потом передает их LLM для формулирования ответа.
- В нижнем левом углу интерфейса Memoza LLM переключитесь с опции «Документ» на опцию «Класс»
- Убедитесь, что в средней графе по-прежнему указано «Мои файлы / Файлы для LLM»
- Теперь задавайте свои вопросы
Загрузив среди прочих документов билет на Сапсан, можно спросить «Когда Василий ездил в Питер» и получить правильный ответ.
Обратите внимание, что в правой части экрана, содержащего ответ LLM, есть кнопочка «i». Нажмите на нее и увидите названия и фрагменты документов, на базе которых LLM подготовила свой ответ.


Этот режим существует для автоматизации процесса назначения атрибутов загруженным документам. Если вы делали все по инструкции, то в основном интерфейсе Memoza вы заметите, что поле «Description» (вторая по счету колонка) осталось незаполненным.
Мы можем заполнить его с помощью LLM для всех загруженных документов разом, воспользовавшись готовым промптом:
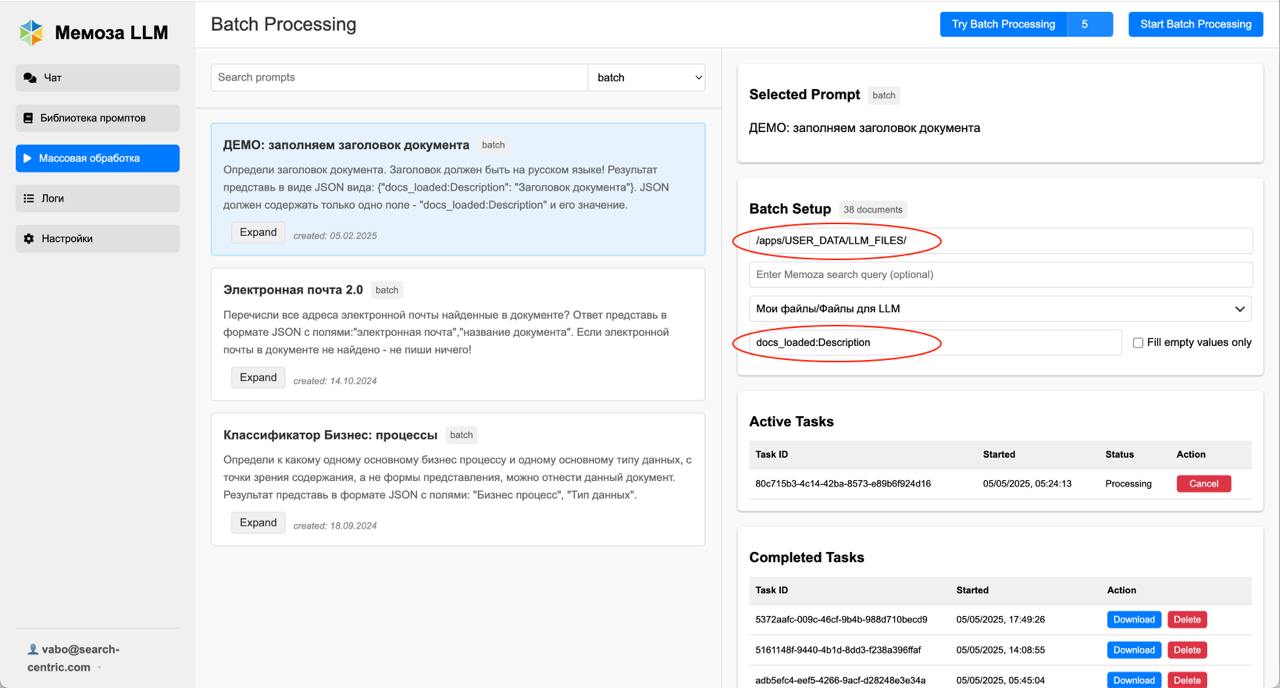
- В интерфейсе Memoza LLM в левой панели перейдите в раздел «Массовая обработка»
- В левой части экрана в правом верхнем углу выберите категорию промптов «batch» и готовый промпт «ДЕМО: заполняем заголовок документа»
- В правой части вставьте путь к папке, куда загружены ваши документы (как правило, это /apps/USER_DATA/LLM_FILES/). Этот путь можно взять из пути к файлу, который вы копировали на Шаге 3
- Поле с поисковым запросом «enter Memoza search query (optional)» оставьте пустым, если не хотите ограничивать выборку обрабатываемых файлов
- В поле «Select class» выберите «Мои файлы/Файлы для LLM» (Система посчитает количество файлов к обработке. Их количество появится рядом с заголовком раздела «Batch processing» чуть выше.)
- В поле «Field mapping…» вставьте системное имя поля, в которое LLM будет записывать результат. В нашем примере просто скопируйте его из текста промпта: «docs_loaded:Description»
- В правом верхнем углу экрана нажмите кнопку «Start Batch Processing»
В блоке «Active tasks» появится задание, которое в зависимости от количества файлов может занять одну-две минуты. Как только задание пропало из «Active tasks», оно появится в разделе «Completed tasks».
По кнопке «Download» можно скачать CSV файл с результатами работы модели.
Теперь перейдите в основной экран Memoza, нажмите поиск или перезагрузите экран, перейдите в ваш класс Мои файлы / Файлы для LLM и убедитесь, что теперь поле «Description» заполнено заголовками соответствующих документов, которые сгенерировала модель.
Пример использования
Вы были на конференции, и вам прислали 20 презентаций в PDF или PPT. Вы загружаете файлы и генерируете заголовки презентаций с помощью массовой обработки. Результат можно выгрузить в Excel, и вот у вас уже есть список презентаций с заголовками.
Создание собственных промптов
Если вы хотите отдельно выделить авторов презентаций, основную мысль, компанию, от которой делалась презентация, то можно использовать дополнительные поля. В основном интерфейсе Memoza, там, где вы видите таблицу с загруженными вами файлами, сдвиньте скроллер вправо - вы увидите пустые колонки с заголовками kmeta:Custom_1 … kmeta:Custom_5. Наполните их нужными вам значениями.
Создание своего первого промпта для массовой обработки:
- В интерфейсе Memoza LLM перейдите в раздел «Библиотека промптов» в левой панели
- В правом верхнем углу выберите категорию промптов «batch» и скопируйте текст готового промпта «ДЕМО: заполняем заголовок документа»
- В правом верхнем углу нажмите «Add new prompt»
- Вставьте скопированное тело промпта в поле «Content», придумайте ему заголовок и категорию так, чтобы вам удобно было его найти в разделе массовой обработки
- Отредактируйте текст промпта: «docs_loaded:Description» замените на «kmeta:Custom_1», и в тексте вместо требования определить заголовок документа напишите, например: «Определи авторов документа. ФИО авторов должны следовать через запятую…»
- Нажмите «Save»
- Вернитесь в раздел «Массовая обработка» и в левой части экрана найдите свой промпт (возможно, понадобится обновить страницу, чтобы он появился)
Все готово! Теперь вы можете повторить действия Шага 5 «Массовая обработка» уже со своим промптом, чтобы заполнить колонку «kmeta:Custom_1» списками авторов документов, и так далее.